安装模块
安装requests,pip install requests
可以直接在pycharm的终端中安装
网络问题可以去国内源下载 pip install -i https://xxx
简单爬虫
在浏览器地址栏中的链接都是使用的GET方式提交
resp.可获取网页中请求的不同内容
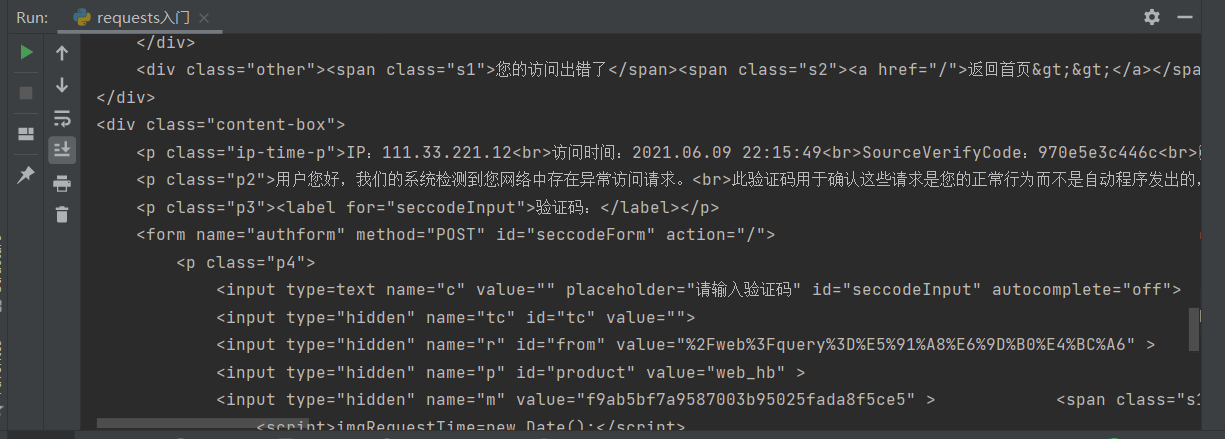
结果被浏览器认为是程序发出的请求,需要绕过
获取user-Agent,模拟成正常浏览器
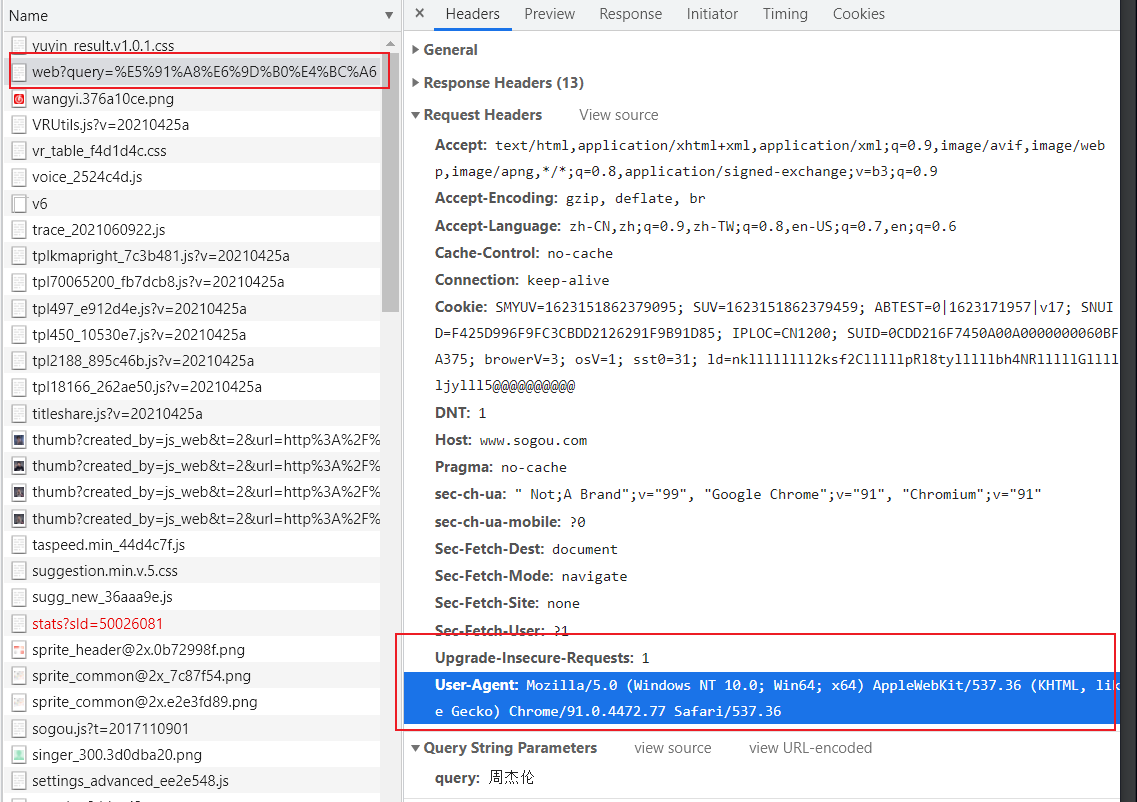
添加一个变量
1
2
3
4
5
6
7
8
9
10
11
12
13
| import requests
url = 'https://www.sogou.com/web?query=周杰伦'
dic = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36"
}
resp = requests.get(url, headers=dic)
print(resp)
print(resp.text)
|
通用化
GET方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import requests
query = input("请输入名称:")
url = f'https://www.sogou.com/web?query={query}'
dic = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36"
}
resp = requests.get(url, headers=dic)
print(resp)
print(resp.text)
|
post方式
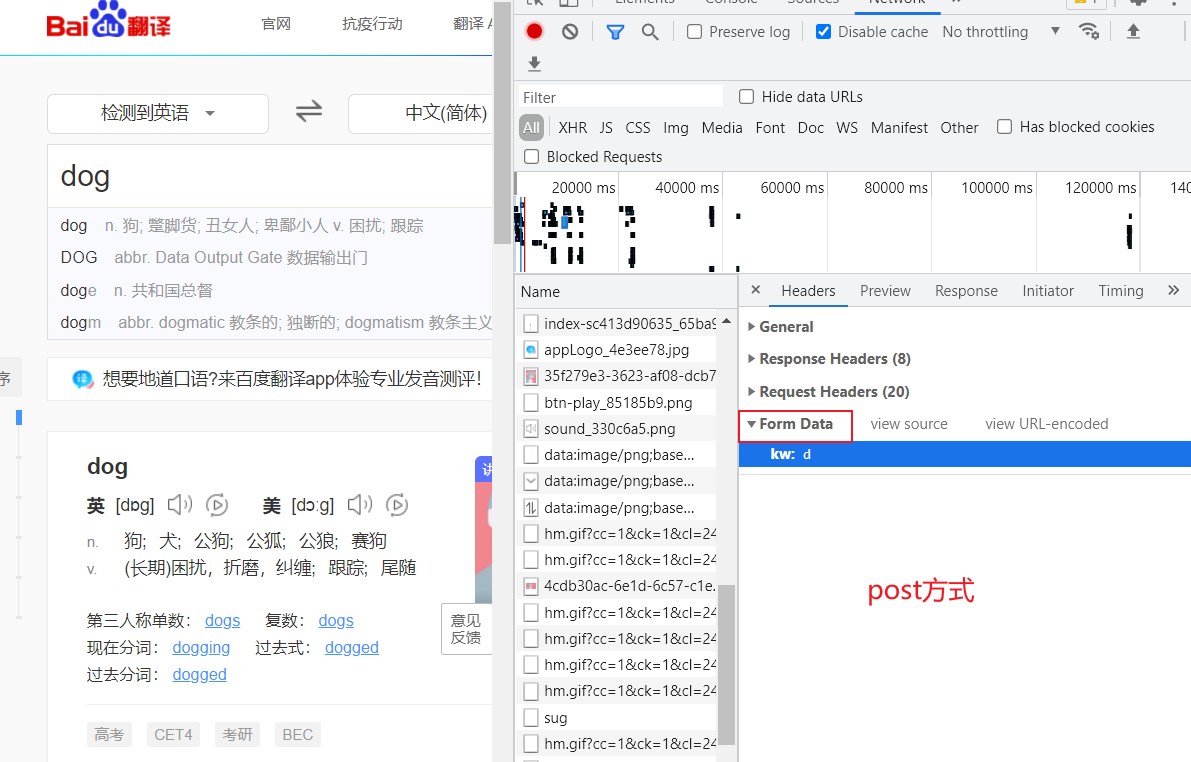
1
2
3
4
5
6
7
8
9
10
11
| import requests
url = "https://fanyi.baidu.com/sug"
s = input("请输入要翻译的英文单词:")
dat = {
"kw": s
}
resp = requests.post(url,data=dat)
print(resp.json())
|
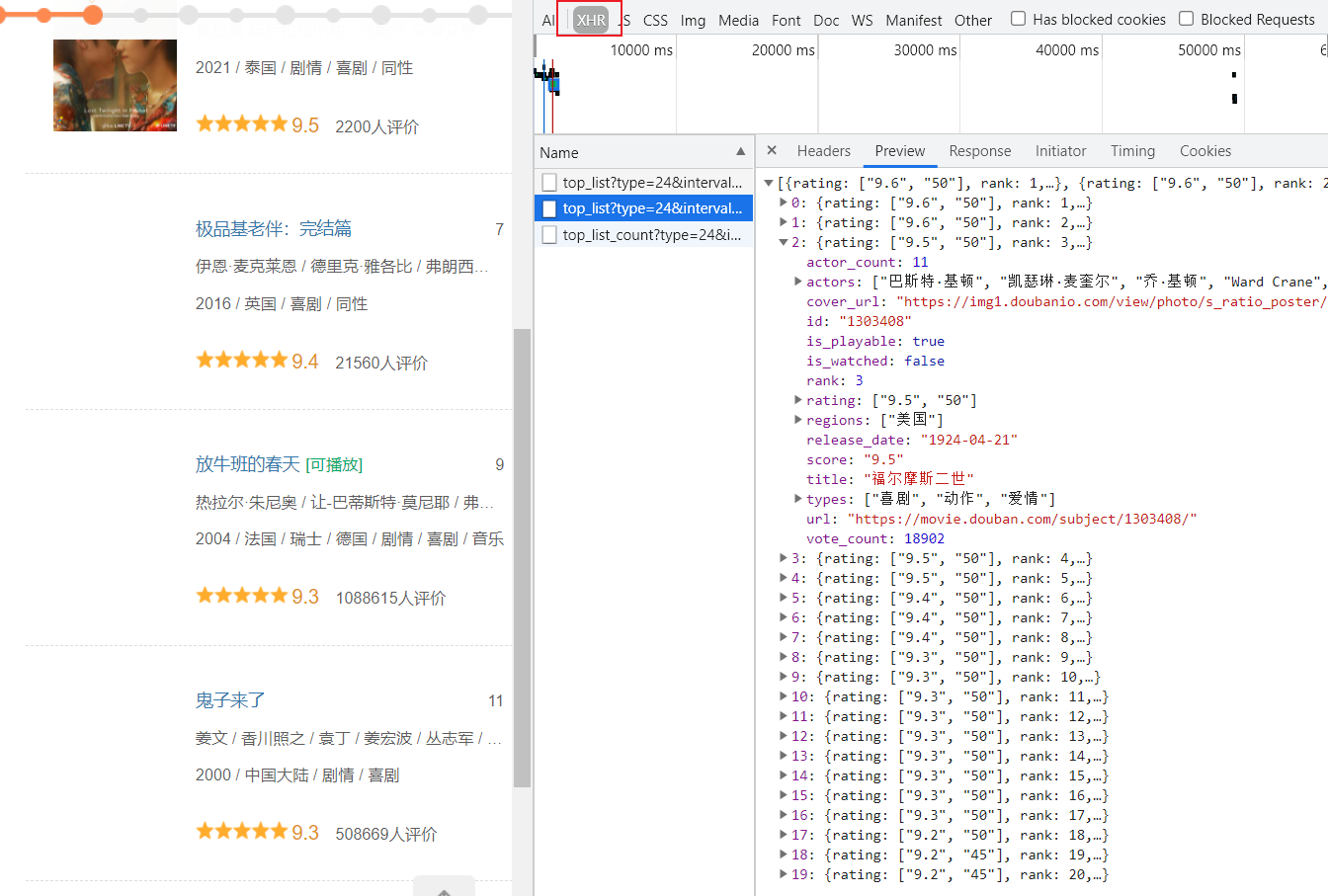
XHR等过滤器
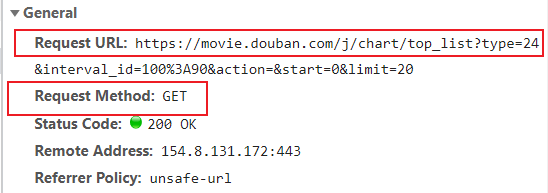
Request URL: https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=0&limit=20
?前面是url,后面是参数
三大块:
-
url
-
请求方式
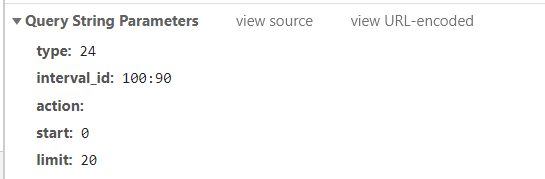
-
参数
如果不能用双引号等直接把字符串等包起来,就打开这里
pycharm运行结果不自动换行,打开这里
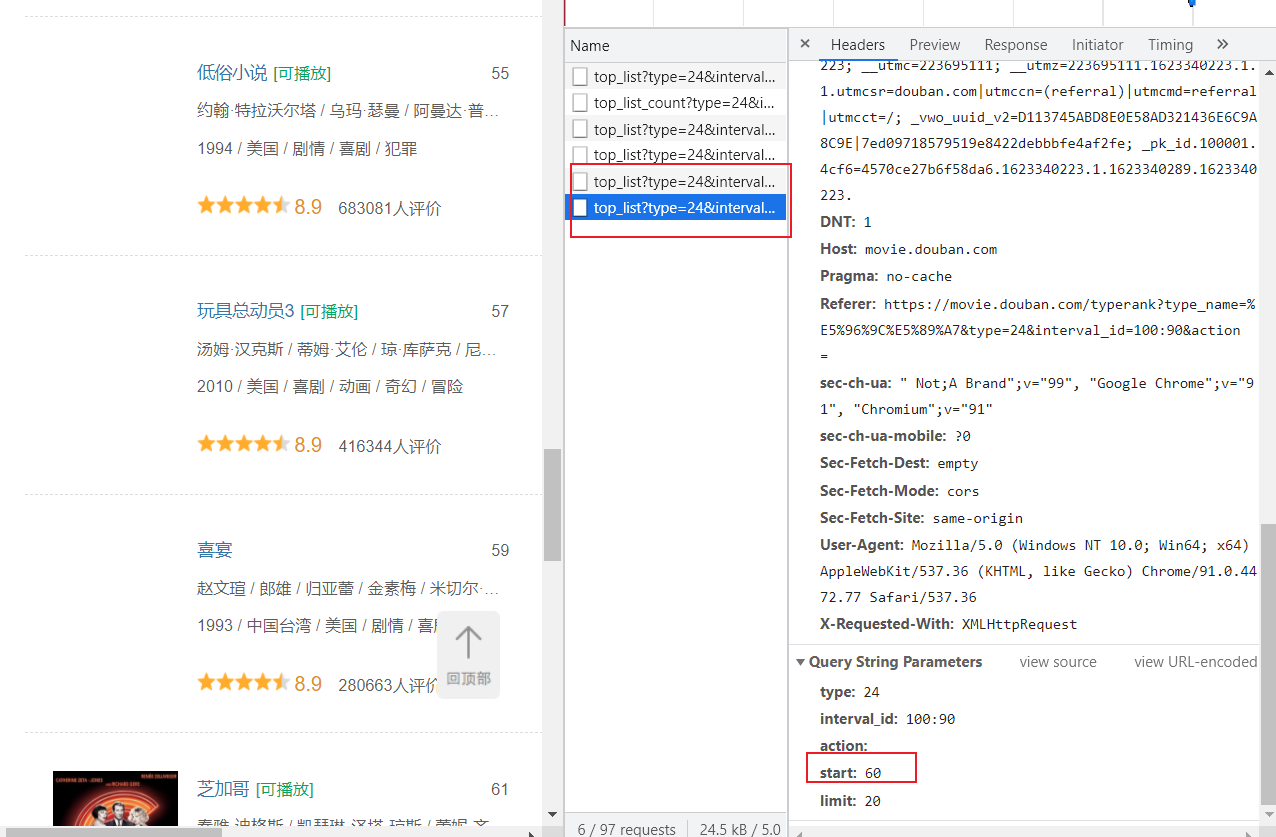
加载新数据会更改start的值
封装参数/处理反爬
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
url = "https://movie.douban.com/j/chart/top_list"
param = {
"type": "24",
"interval_id": "100:90",
"action": "",
"start": "0",
"limit": "20",
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36"
}
resp = requests.get(url=url,params=param,headers=headers)
print(resp.text)
resp.close()
|
