1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
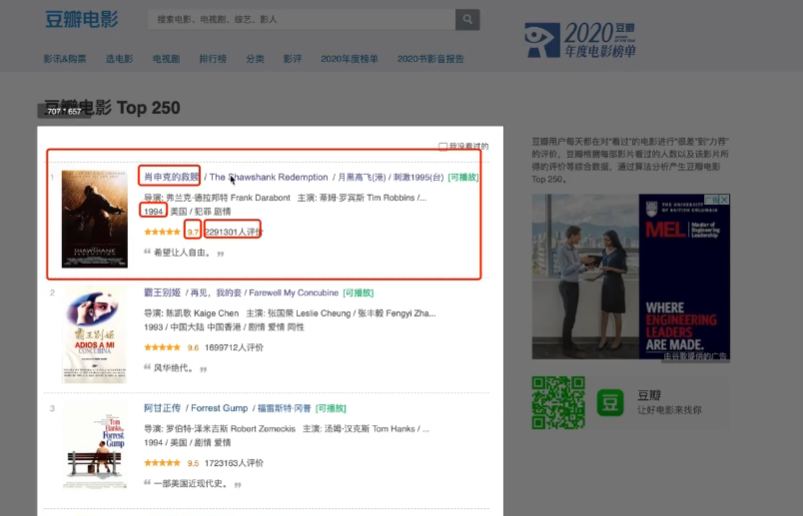
| 肖申克的救赎,1994,9.7,2367456
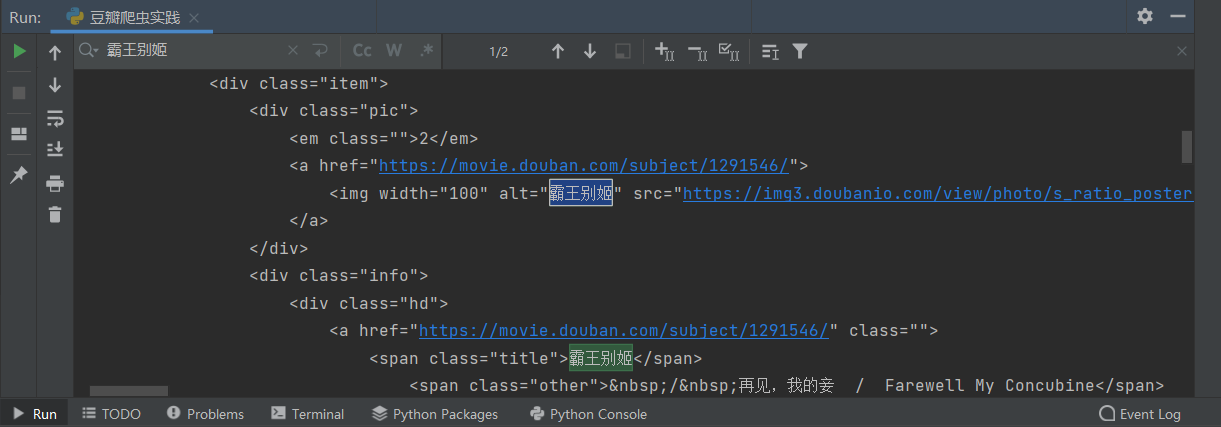
霸王别姬,1993,9.6,1762938
阿甘正传,1994,9.5,1783969
这个杀手不太冷,1994,9.4,1956540
泰坦尼克号,1997,9.4,1744908
美丽人生,1997,9.5,1096478
千与千寻,2001,9.4,1860281
辛德勒的名单,1993,9.5,910424
盗梦空间,2010,9.3,1720536
忠犬八公的故事,2009,9.4,1181974
星际穿越,2014,9.3,1393187
楚门的世界,1998,9.3,1309969
海上钢琴师,1998,9.3,1397593
三傻大闹宝莱坞,2009,9.2,1570301
机器人总动员,2008,9.3,1104595
放牛班的春天,2004,9.3,1089081
无间道,2002,9.3,1060992
疯狂动物城,2016,9.2,1538596
大话西游之大圣娶亲,1995,9.2,1272075
熔炉,2011,9.3,771963
教父,1972,9.3,774119
当幸福来敲门,2006,9.1,1262580
龙猫,1988,9.2,1053336
怦然心动,2010,9.1,1495535
控方证人,1957,9.6,372429
|